
|
I am a final-year PhD student at MIT CSAIL advised by Professor Daniela Rus. My research focus is on sample-efficient learning for robot control based on concepts from model-based exploration, architecture simplification, and compositionality. Before joining MIT, I obtained a BSc in Mechanical Engineering and an MSc in Robotics and Control from ETH Zurich under supervision of Professor Marco Hutter. Throughout my studies, I had the opportunity of various research stays and internships in legged robotics as well as learning control, and was fortunate to learn from many brilliant mentors. . |
|
|

|

|
|
|
MIT CSAIL PhD student 09/2018-Present |
ETH Zurich MSc Robotics 09/2015-05/2018 |
University of Tokyo Visiting student 03/2016-08/2016 |
ETH Zurich BSc MechE 09/2011-08/2014 |
|
|

|
|

|
|
DeepMind Research Scientist Intern 06/2022-09/2022 |
IHMC Robotics Research Intern 03/2017-09/2017 |
PAL Robotics Research Intern 04/2015-07/2015 |
DLR Robotics Research Intern 10/2014-04/2015 |
|
I'm interested in reinforcement learning, motion planning, and control. I'm particularly excited about application in (legged) robotics, leveraging learning-based approaches to unlock capabilities that prove challenging for traditional methods. |
|
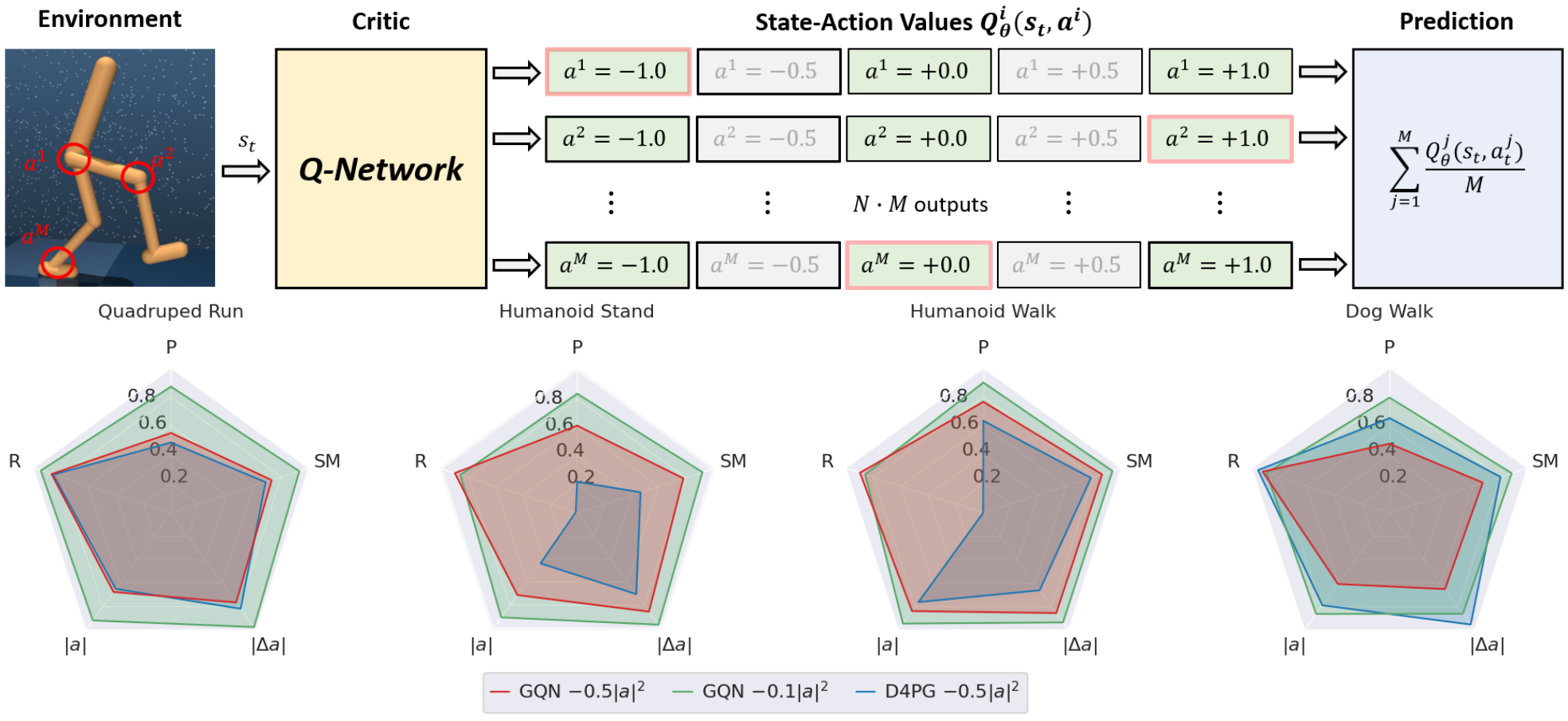
Tim Seyde, Peter Werner, Wilko Schwarting, Markus Wulfmeier, Daniela Rus Preprint, 2023 Summary: we combine the benefits of coarse exploration during learning and smooth control at convergence by growing action spaces via decoupled Q-learning. |
|
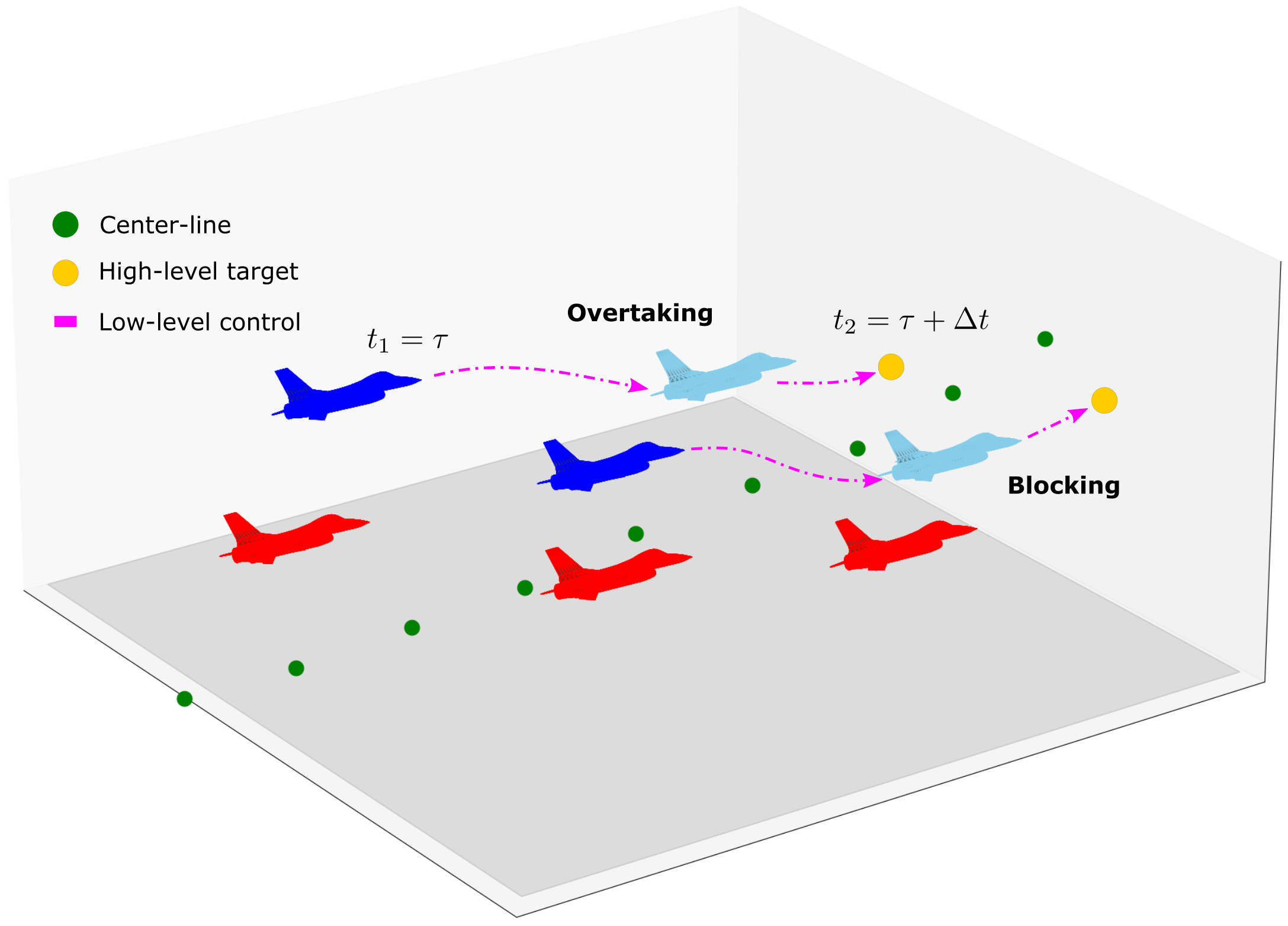
Tim Seyde, Mathias Lechner, Joshua Rountree, Daniela Rus Preprint, 2023 Summary: we leverage a hierarchical policy design for multi-team dynamic flight control, enabling high-level strategic coordination via distributional decoupled RL. |
|
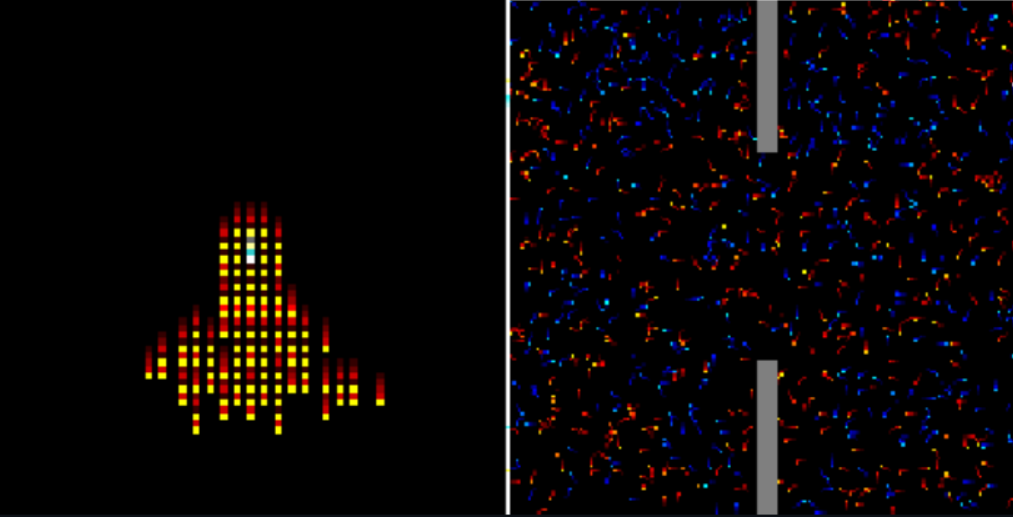
Mathias Lechner, Lianhao Yin, Tim Seyde, Tsun-Hsuan Wang, Wei Xiao, Ramin Hasani, Joshua Rountree, Daniela Rus NeurIPS, 2023 Summary: we present Gigastep, a fully vectorized JAX-based MARL environment that features high-dimensional 3D dynamics, heterogeneous agent types, stochasticity, and partial observation. |

|
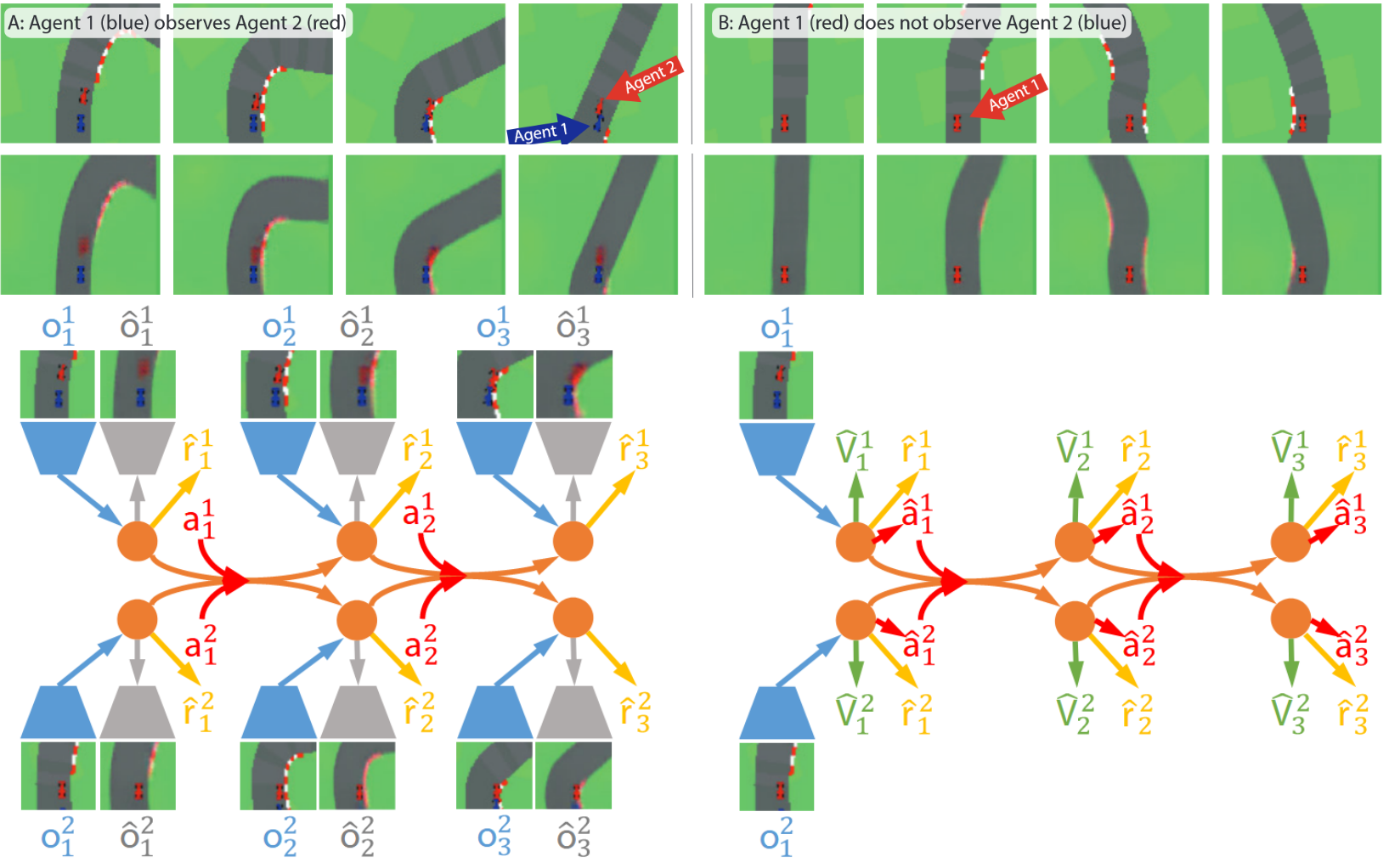
Peter Werner*, Tim Seyde*, Paul Drews, Thomas Balch, Igor Gilitschenski, Wilko Schwarting, Guy Rosman, Sertac Karaman, Daniela Rus CoRL, 2023 + [Best paper award] ICRA Workshop on Multi-Robot Learning, 2023 Summary: we deploy a hierarchical RL agent in multi-team racing scenarios on scale-car hardware, combining decoupled SARSA for team-centric strategic reasoning with continuous PPO for ego-centric low-level decision making. |
|
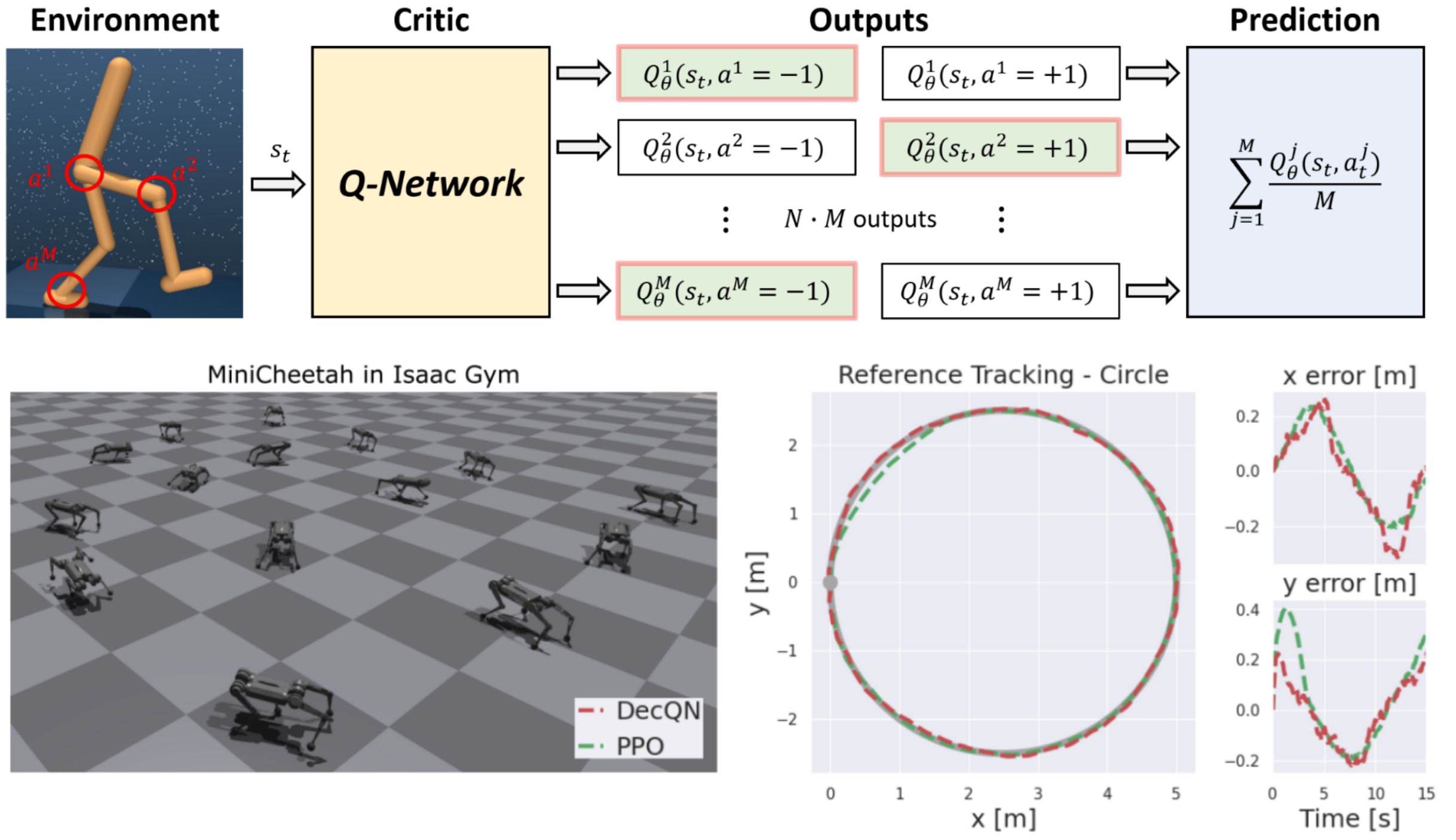
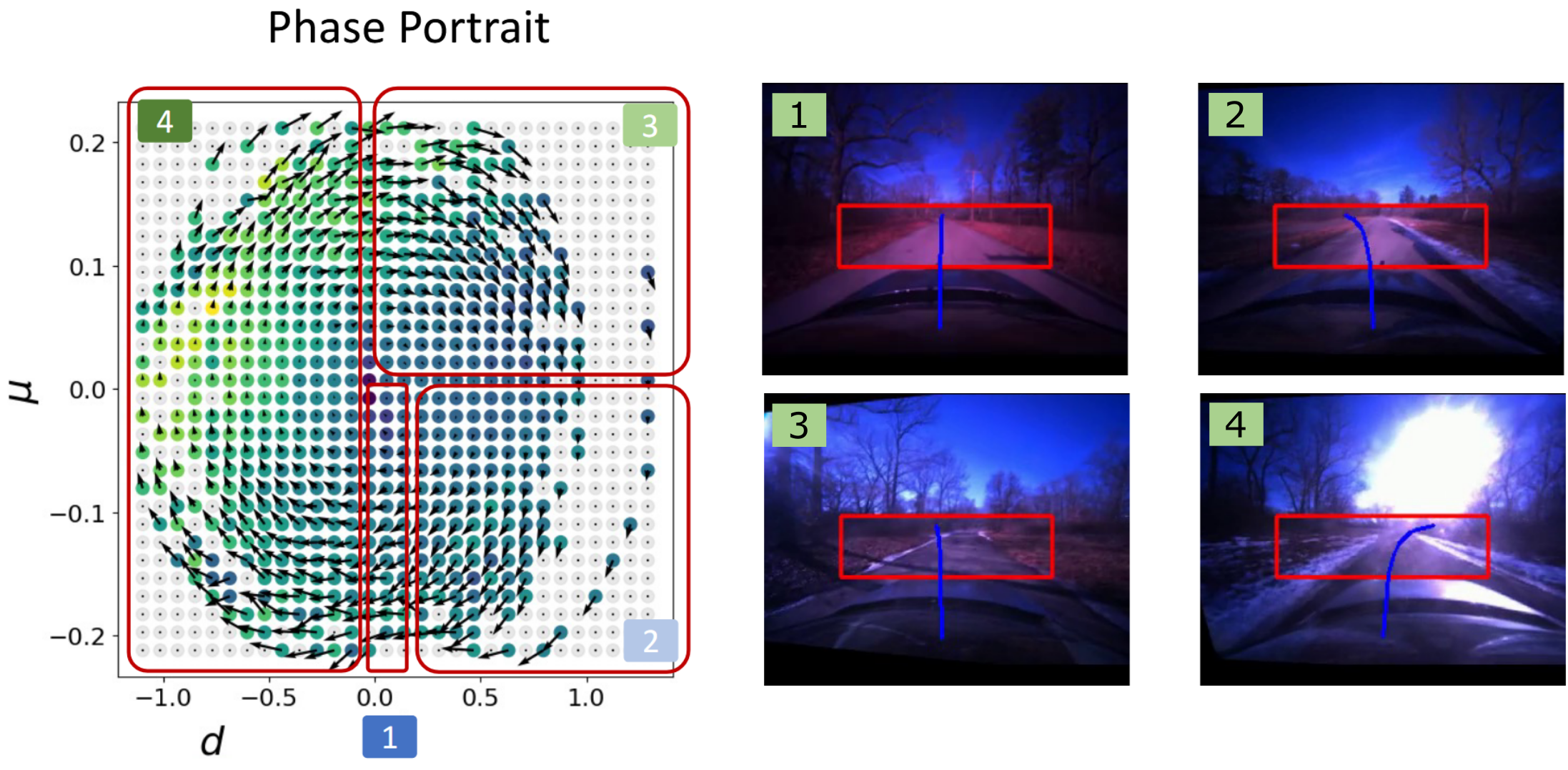
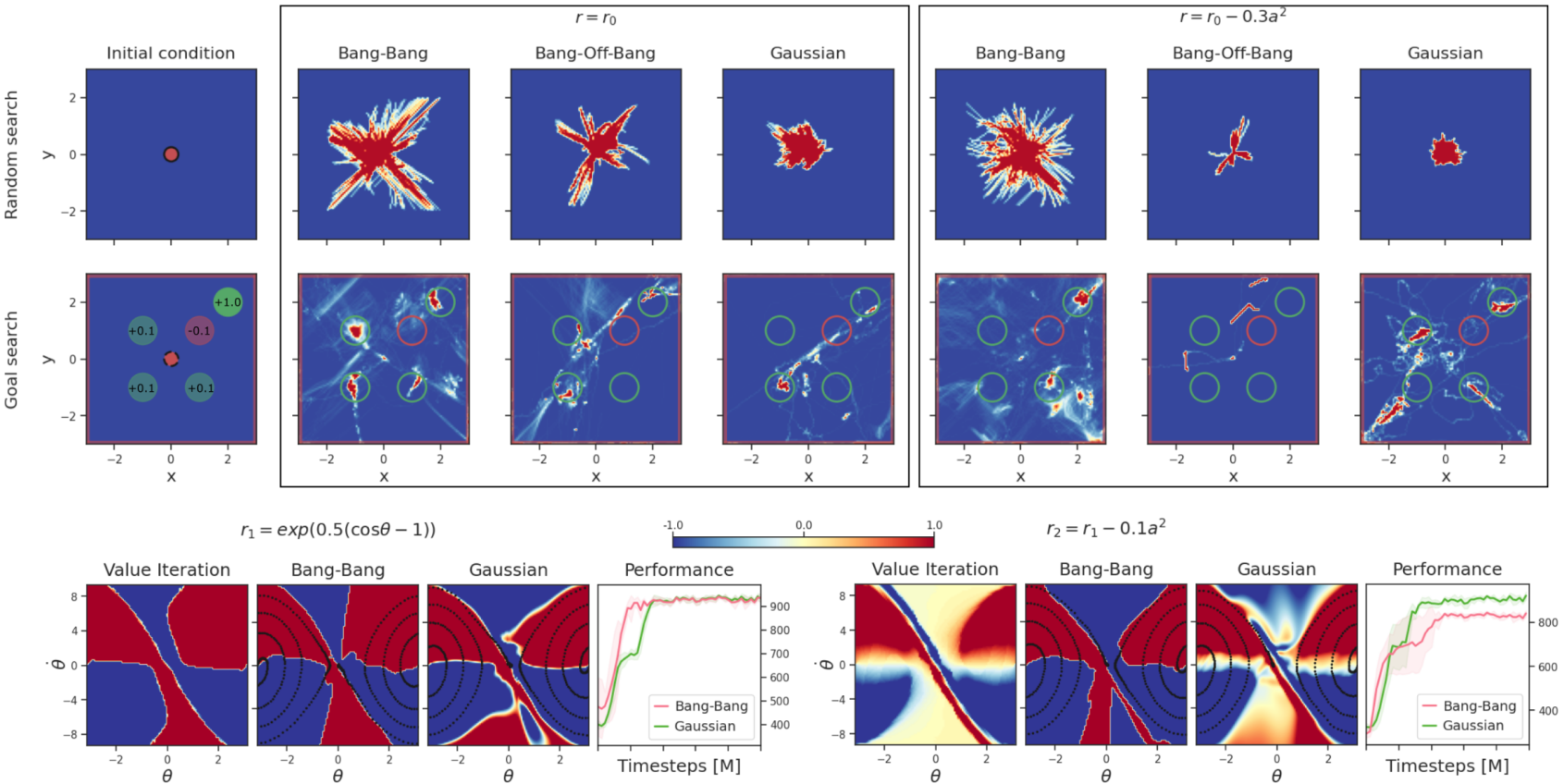
Tim Seyde, Peter Werner, Wilko Schwarting, Igor Gilitschenski, Martin Riedmiller, Daniela Rus, Markus Wulfmeier ICLR, 2023 Summary: we show that DQN combined with value decomposition and bang-bang action space discretization yields performance competitive with recent model-free and model-based actor critic algorithms when training from features or raw pixels. |
|
Tsun-Hsuan Wang, Wei Xiao, Tim Seyde, Ramin Hasani, Daniela Rus [Oral presentation] CoRL, 2023 Summary: we analyze how decision trees based on logic programs extracted from a compact bio-inspired model architecture can help interpretable decision making. |

|
Lianhao Yin, Tsun-Hsuan Wang, Makram Chahine, Tim Seyde, Mathias Lechner, Ramin Hasani, Daniela Rus IROS, 2023 Summary: we investigate a parallel autonomy system for flight based on attention map mismatches with a bio-inspired policy architecture. |
|
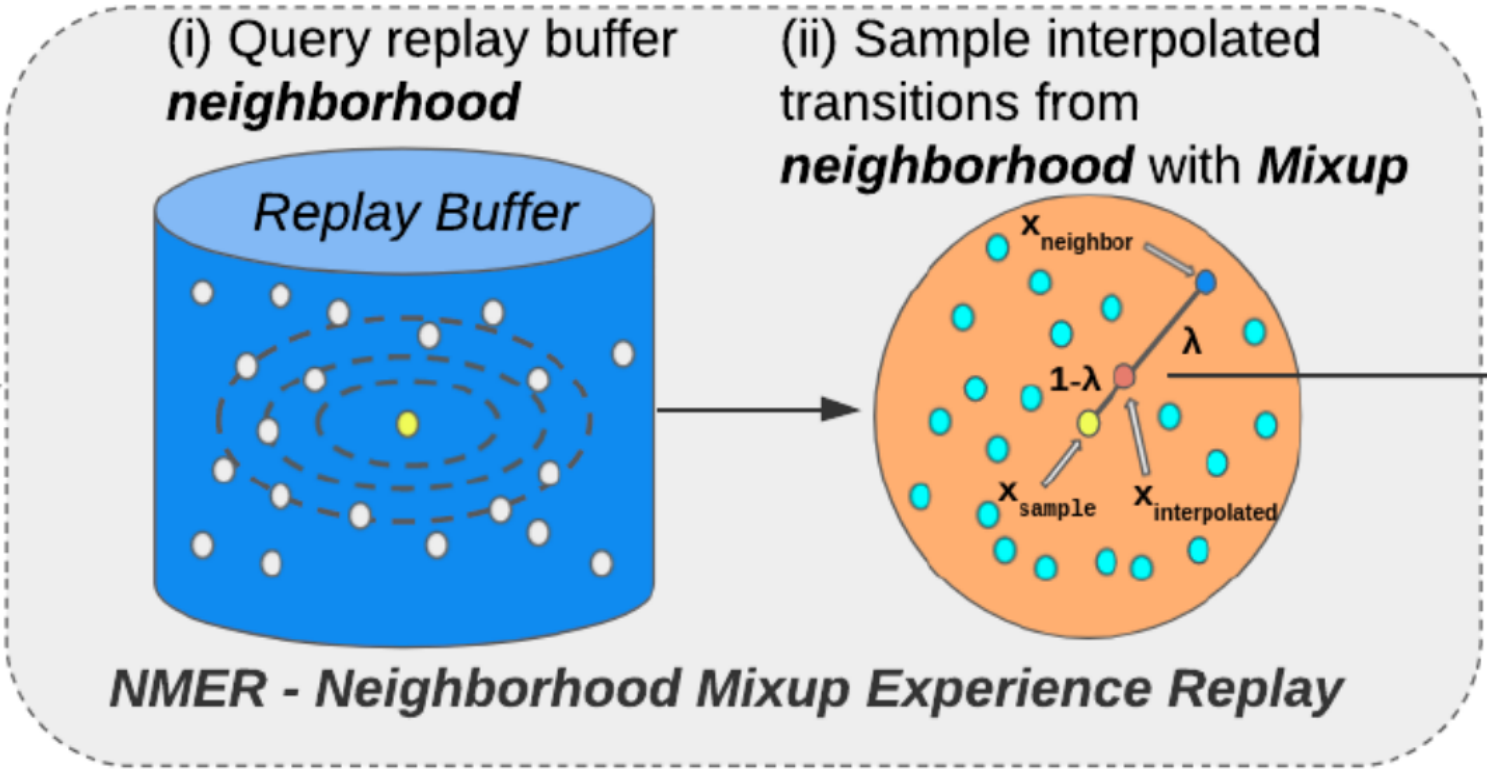
Ryan Sander, Wilko Schwarting, Tim Seyde, Igor Gilitschenski, Sertac Karaman, Daniela Rus L4DC, 2022 Summary: we investigate replay memory interpolation as a data augmentation technique for improving data efficiency of reinforcement learning agents. |
|
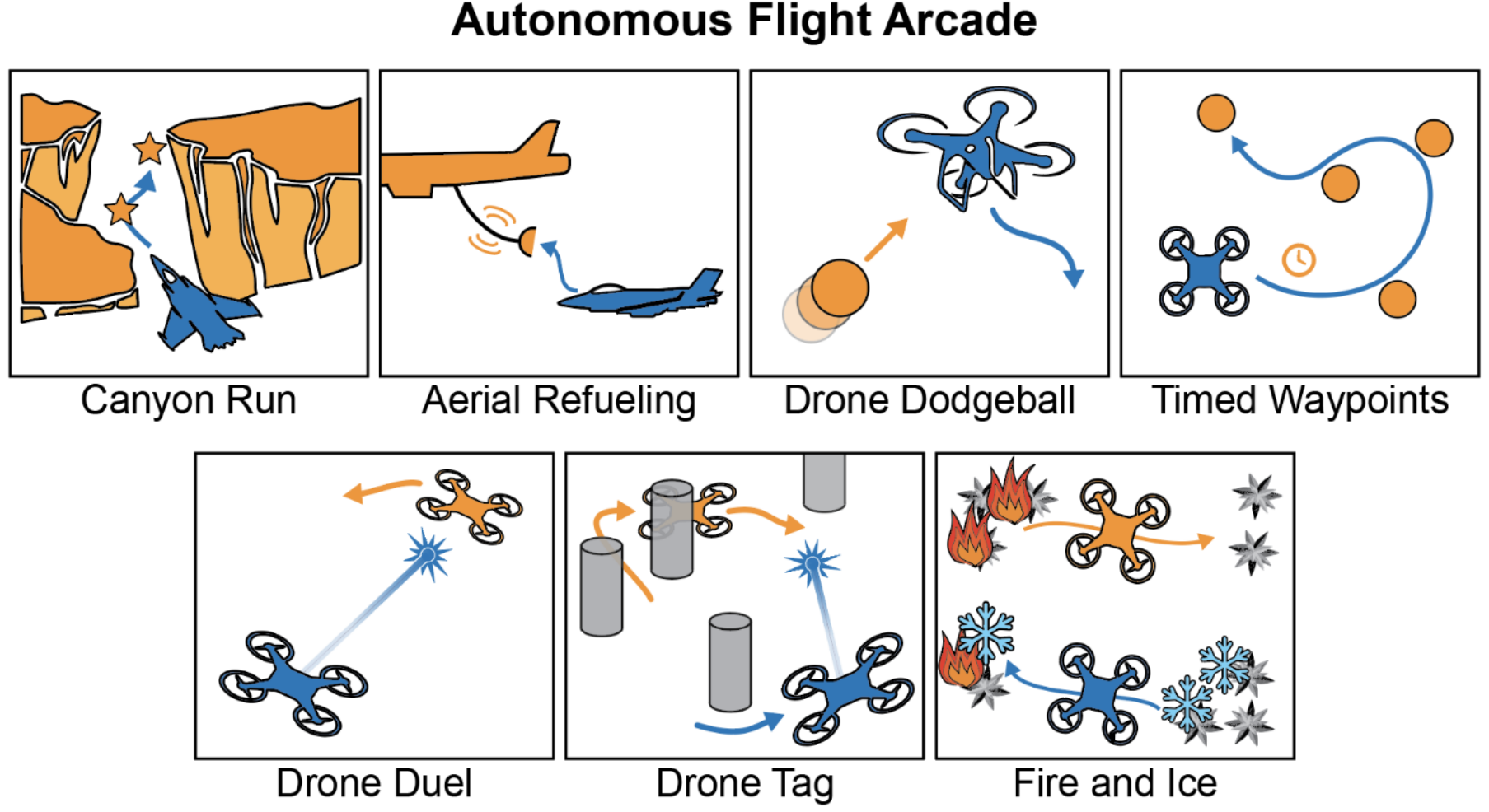
Paul Tylkin, Tsun-Hsuan Wang, Tim Seyde, Kyle Palko, Ross Allen, Alexander Amini, Daniela Rus AAMAS Extended Abstract, 2022 Summary: we propose a suite of challenging problems to test agents in autononmous flight scenarios towards guardian autonomy systems. |
|
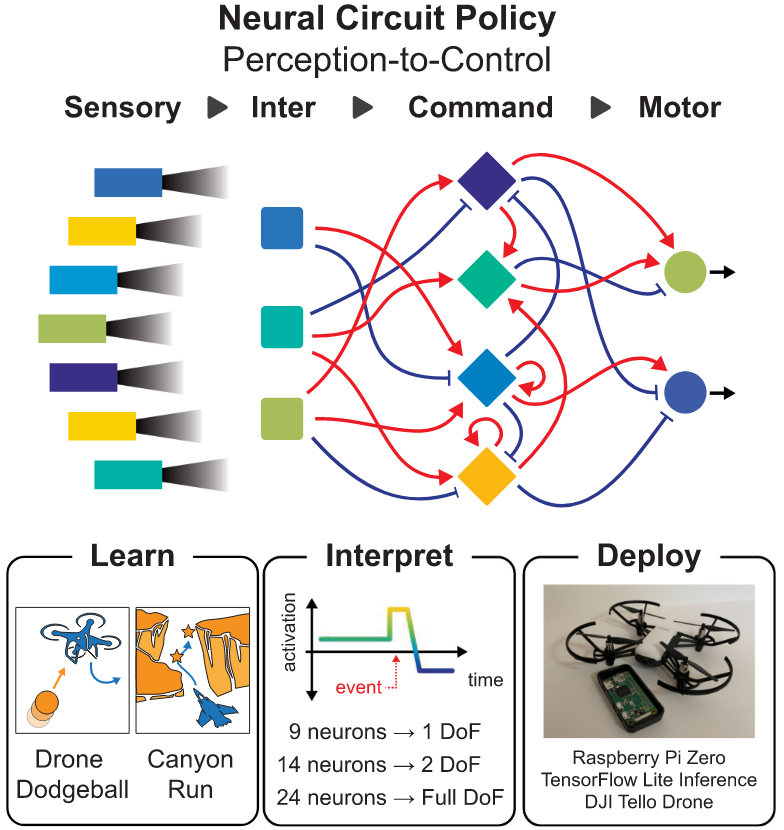
Paul Tylkin, Tsun-Hsuan Wang, Kyle Palko, Ross Allen, Ho Chit Siu, Daniel Wrafter, Tim Seyde, Alexander Amini, Daniela Rus IEEE RAL, 2022 Summary: we show how a bio-inspired model architecture yields compact policies for solving autonomous flight scenarios. |
|
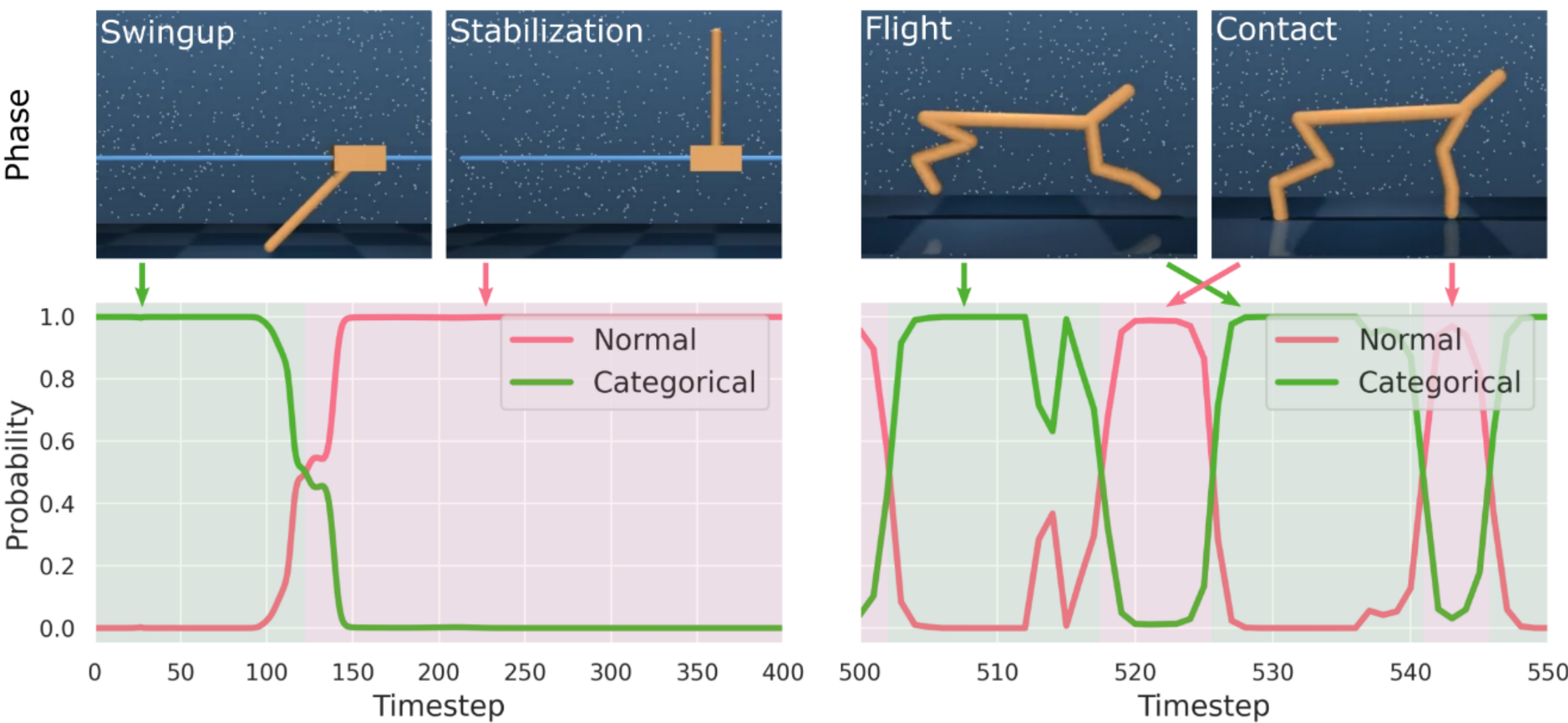
Tim Seyde, Igor Gilitschenski, Wilko Schwarting, Bartolomeo Stellato, Martin Riedmiller, Markus Wulfmeier, Daniela Rus NeurIPS, 2021 Summary: we show that several recent actor critic algorithms yield competitive performance when only considering bang-bang policy heads and discuss implications for agent and benchmark design. |
|
Tim Seyde, Wilko Schwarting, Igor Gilitschenski, Markus Wulfmeier, Daniela Rus CoRL, 2021 Summary: we leverage a hierarchical model over diverse low-level policy architectures to transfer the burden of hyperparameter selection from the engineer to the agent. |
|
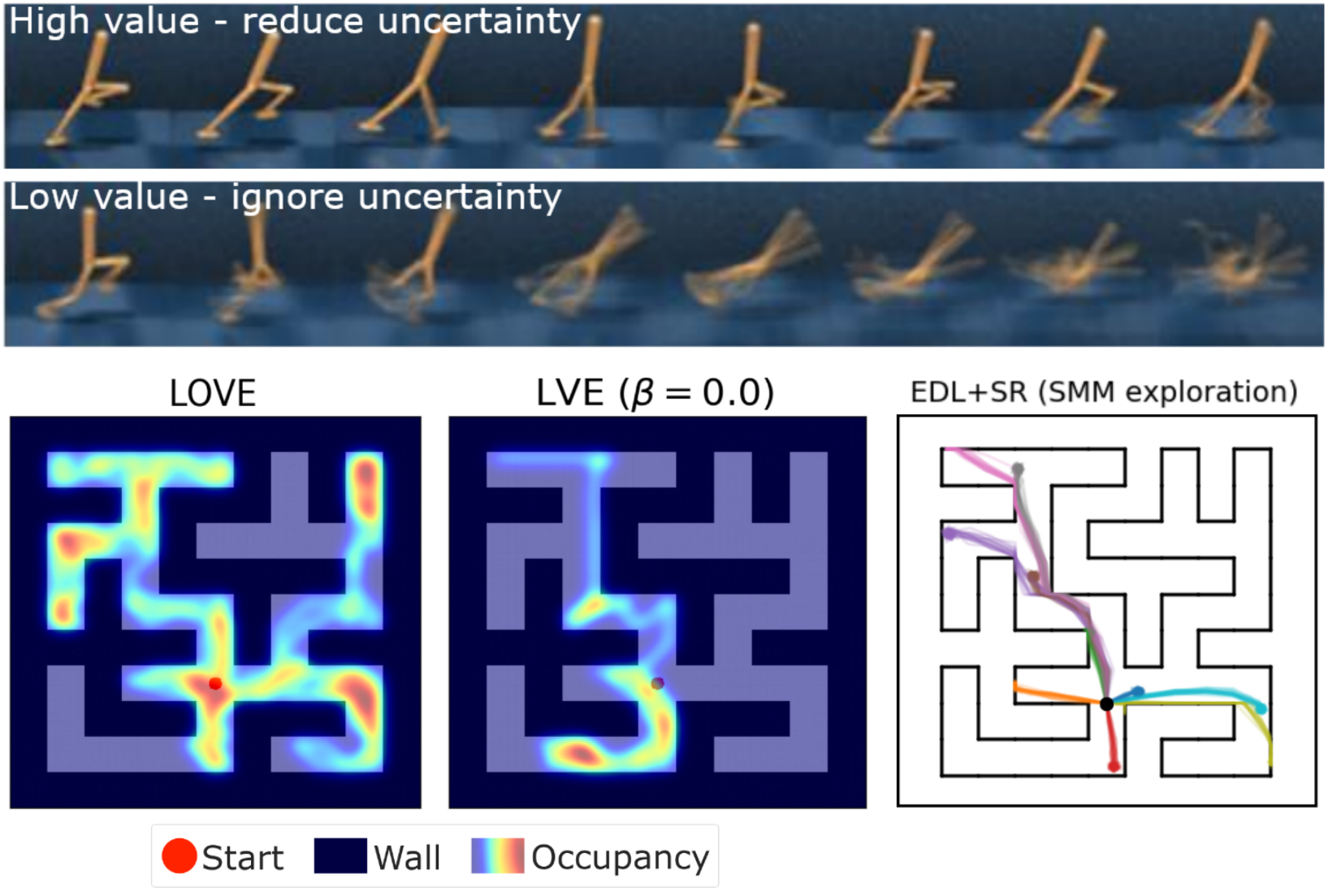
Tim Seyde*, Wilko Schwarting*, Sertac Karaman, Daniela Rus CoRL, 2021 Summary: we leverage a latent model ensemble to compute an upper confindence bound objective over predicted returns to guide exploration in continuous control from pixels. |
|
Wilko Schwarting*, Tim Seyde*, Igor Gilitschenski*, Lucas Liebenwein, Ryan Sander, Sertac Karaman, Daniela Rus CoRL, 2020 Summary: we leverage self-play in latent space with a world model that estimates opponent behavior to generate competitive racing maneuvers. |
|
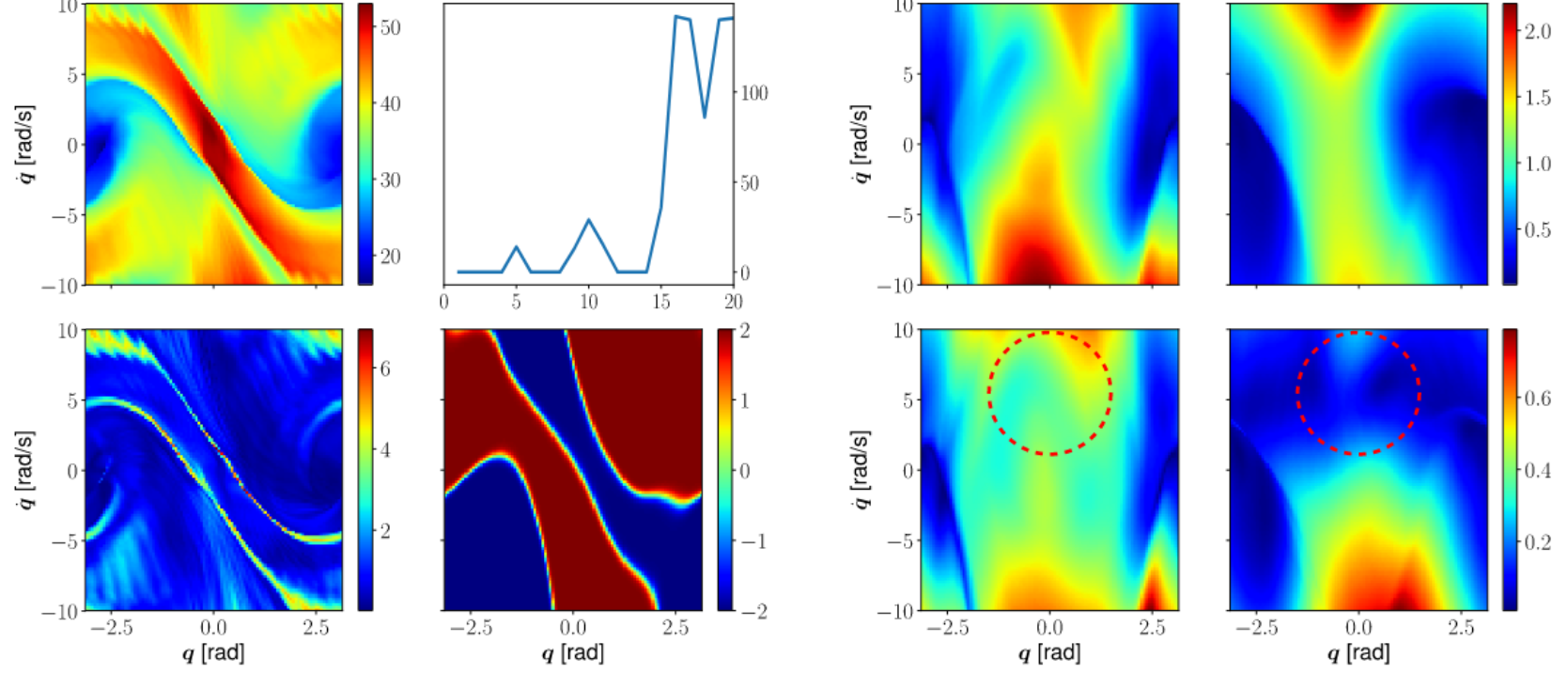
Tim Seyde*, Wilko Schwarting*, Sertac Karaman, Daniela L Rus L4DC, 2020 Summary: we learn a value function that represents an upper confidence bound over expected returns to guide exploration in continuous control from features. |
|
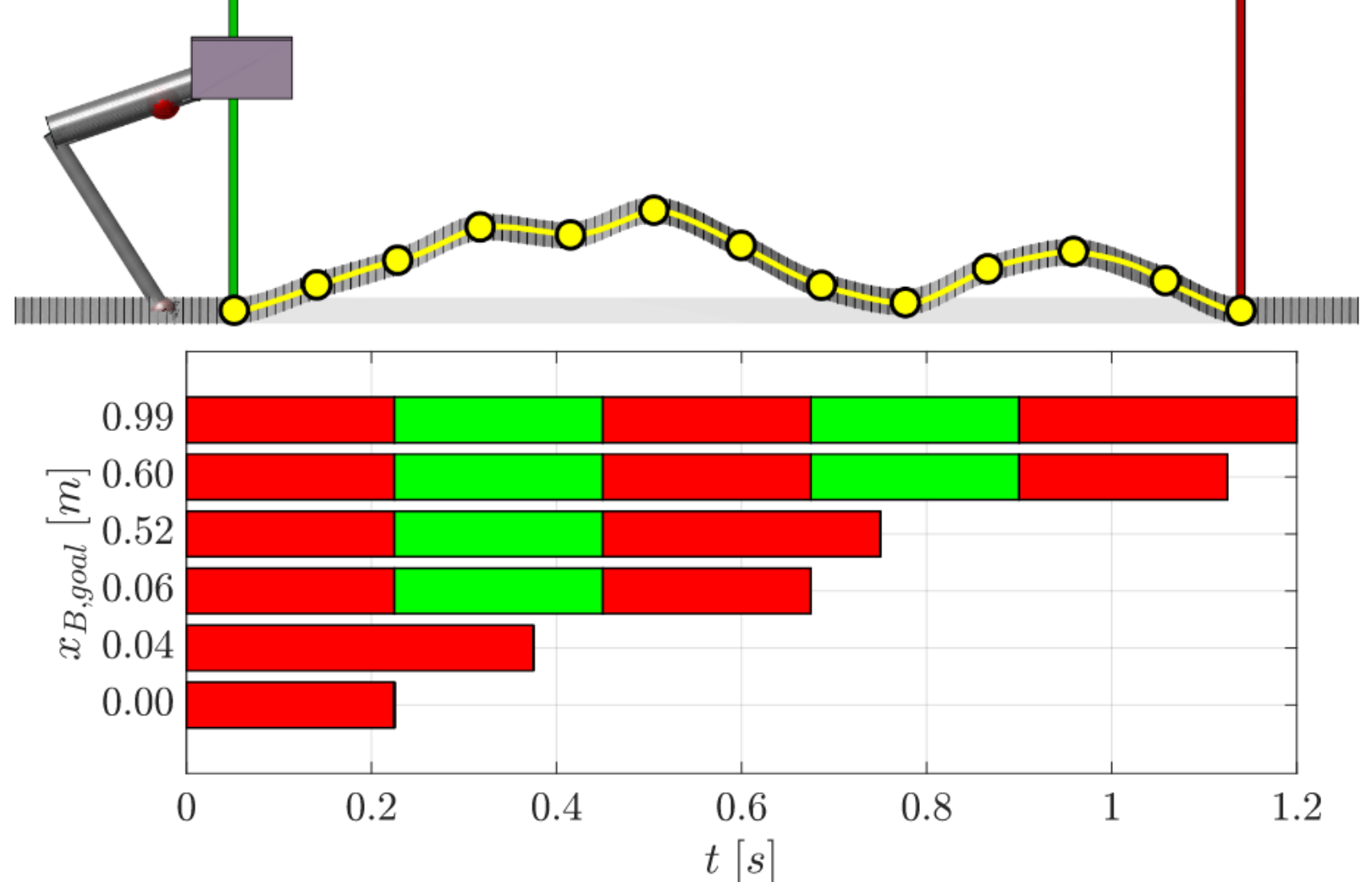
Tim Seyde, Jan Carius, Ruben Grandia, Farbod Farshidian, Marco Hutter ICRA, 2019 Summary: we solve a mixed-integer gait planning problem for a single-legged hopper by learning footstep selection with a Gaussian process, and using this to constrain a low-level trajectory planner. |

|
Tim Seyde, Apoorv Shrivastava, Johannes Englsberger, Sylvain Bertrand, Jerry Pratt, Robert J Griffin ICRA, 2018 Summary: we augment a capture-point based walking controller to account for swing-leg angular momentum during reference trajectory planning and show improved locomotion capabilities with an Atlas humanoid robot. |
|
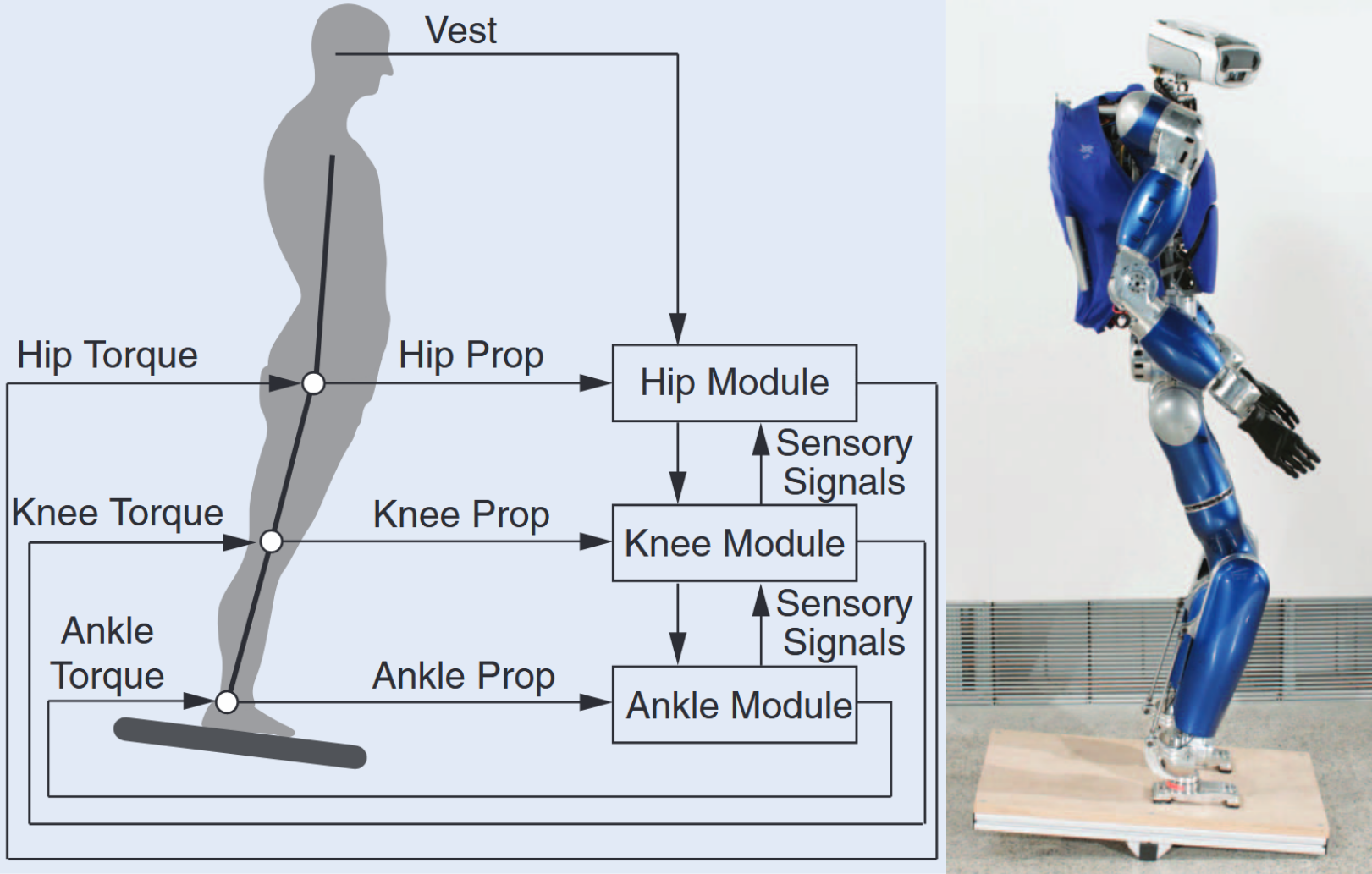
Christian Ott, Bernd Henze, Georg Hettich, Tim Seyde, Máximo A Roa, Vittorio Lippi, Thomas Mergner IEEE RAM, 2016 Summary: we implement a bio-inspired modular posture controller and compare to model-based control on disturbance compensations tasks with the TORO humanoid. |